MySQL 9.0 發行說明
- 25.7.1 NDB Cluster 複寫:縮寫和符號
- 25.7.2 NDB Cluster 複寫的一般需求
- 25.7.3 NDB Cluster 複寫中已知問題
- 25.7.4 NDB Cluster 複寫架構和資料表
- 25.7.5 準備 NDB Cluster 進行複寫
- 25.7.6 啟動 NDB Cluster 複寫 (單一複寫通道)
- 25.7.7 使用兩個複寫通道進行 NDB Cluster 複寫
- 25.7.8 使用 NDB Cluster 複寫實作容錯移轉
- 25.7.9 使用 NDB Cluster 複寫進行 NDB Cluster 備份
- 25.7.10 NDB Cluster 複寫:雙向和循環複寫
- 25.7.11 使用多執行緒應用程式的 NDB Cluster 複寫
- 25.7.12 NDB Cluster 複寫衝突解決
NDB Cluster 支援非同步複寫,通常簡稱為 「複寫」。本節說明如何設定和管理一個配置,其中一組作為 NDB Cluster 運作的電腦複寫到第二個電腦或一組電腦。我們假設讀者對本手冊其他章節中討論的標準 MySQL 複寫有所了解。(請參閱 第 19 章,複寫)。
注意
NDB Cluster 不支援使用 GTID 的複寫; NDB 儲存引擎也不支援半同步複寫和群組複寫。
一般(非叢集)複寫涉及一個來源伺服器和一個複本伺服器,來源伺服器之所以如此命名,是因為要複寫的操作和資料源自於它,而複本伺服器則是這些操作和資料的接收者。在 NDB Cluster 中,複寫在概念上非常相似,但在實務上可能更複雜,因為它可以擴展到涵蓋許多不同的配置,包括在兩個完整的叢集之間進行複寫。雖然 NDB Cluster 本身依賴 NDB 儲存引擎以實現叢集功能,但不必使用 NDB 作為複本複製資料表的儲存引擎(請參閱 從 NDB 複寫到其他儲存引擎)。但是,為了獲得最大的可用性,最好(也建議)從一個 NDB Cluster 複寫到另一個 NDB Cluster,這也是我們討論的情境,如下圖所示
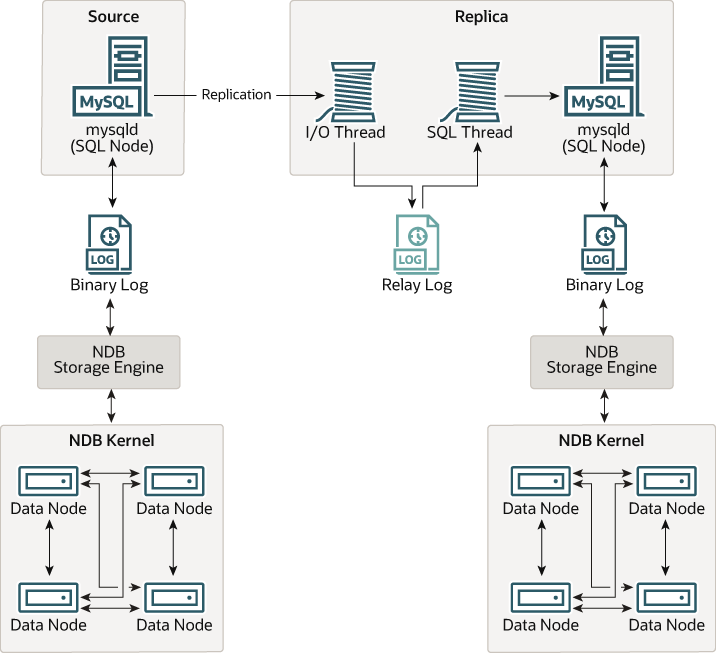
在此情境中,複寫過程是將來源叢集的連續狀態記錄並儲存到複本叢集中。此過程由一個稱為 NDB 二進制日誌注入器執行緒的特殊執行緒完成,該執行緒在每個 MySQL 伺服器上執行,並產生一個二進制日誌 (binlog)。此執行緒確保產生二進制日誌的叢集中的所有變更(而不僅僅是透過 MySQL Server 執行的變更)都以正確的序列化順序插入到二進制日誌中。我們將 MySQL 來源和複本伺服器稱為複寫伺服器或複寫節點,它們之間的資料流或通訊線路稱為複寫通道。
有關使用 NDB Cluster 和 NDB Cluster 複寫執行時間點復原的資訊,請參閱第 25.7.9.2 節,「使用 NDB Cluster 複寫進行時間點復原」。
NDB API 複本狀態變數。 NDB API 計數器可以在複本叢集上提供增強的監控功能。這些計數器實作為 NDB 統計資料 _replica 狀態變數,如 SHOW STATUS 的輸出中所示,或是在連線到 MySQL Server 的 mysql 用戶端工作階段中,針對 Performance Schema session_status 或 global_status 資料表查詢的結果中所示,該 MySQL Server 在 NDB Cluster 複寫中充當複本。透過比較影響複寫 NDB 資料表的陳述式執行前後的這些狀態變數的值,您可以觀察到複本在 NDB API 層次採取的相應動作,這在監控或疑難排解 NDB Cluster 複寫時非常有用。 第 25.6.16 節,「NDB API 統計計數器和變數」,提供了其他資訊。
從 NDB 複寫到非 NDB 資料表。可以從充當複寫來源的 NDB Cluster 將 NDB 資料表複寫到複本 mysqld 上使用其他 MySQL 儲存引擎(如 InnoDB 或 MyISAM)的資料表。這受到一些條件的約束;請參閱從 NDB 複寫到其他儲存引擎和 從 NDB 複寫到非交易儲存引擎以取得更多資訊。