MySQL 9.0 發行說明
NDB Cluster 是一種技術,可讓在無共用系統中叢集記憶體內資料庫。無共用架構可讓系統使用非常低廉的硬體,並且對硬體或軟體的需求降到最低。
NDB Cluster 的設計目的是不具備任何單點故障。在無共用系統中,每個元件都應該有自己的記憶體和磁碟,且不建議或不支援使用網路共用、網路檔案系統與 SAN 等共用儲存機制。
NDB Cluster 將標準的 MySQL 伺服器與名為 NDB (代表 「Network DataBase」) 的記憶體內叢集儲存引擎整合。在我們的文件中,術語 NDB 是指設定中專屬於儲存引擎的部分,而 「MySQL NDB Cluster」 則是指一個或多個 MySQL 伺服器與 NDB 儲存引擎的組合。
NDB Cluster 由一組稱為 主機 的電腦組成,每個電腦都執行一個或多個程序。這些程序稱為 節點,可能包含 MySQL 伺服器 (用於存取 NDB 資料)、資料節點 (用於儲存資料)、一個或多個管理伺服器,以及其他可能專用的資料存取程式。此處顯示 NDB Cluster 中這些元件的關係
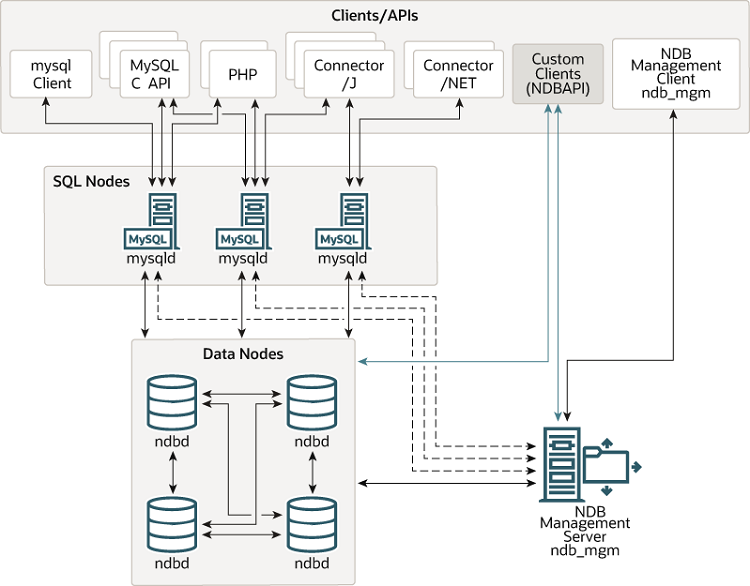
所有這些程式共同運作以形成 NDB Cluster (請參閱第 25.5 節 「NDB Cluster 程式」)。當 NDB 儲存引擎儲存資料時,表格 (與表格資料) 會儲存在資料節點中。此類表格可直接從叢集中的所有其他 MySQL 伺服器 (SQL 節點) 存取。因此,在叢集中儲存資料的薪資應用程式中,如果一個應用程式更新了員工的薪資,則所有查詢此資料的其他 MySQL 伺服器都會立即看到此變更。
NDB Cluster 9.0 SQL 節點會使用 mysqld 伺服器常駐程式,該常駐程式與 MySQL Server 9.0 發行版本隨附的 mysqld 相同。您應該記住,無論版本為何,未連線到 NDB Cluster 的 mysqld 執行個體都無法使用 NDB 儲存引擎,且無法存取任何 NDB Cluster 資料。
NDB Cluster 的資料節點中儲存的資料可以鏡像;叢集可以處理個別資料節點的失敗,且除了因遺失交易狀態而中止少數交易之外,不會造成其他影響。因為交易應用程式應該要處理交易失敗,所以這不應該是問題的來源。
可以停止並重新啟動個別節點,然後重新加入系統 (叢集)。滾動重新啟動 (依序重新啟動所有節點) 用於進行組態變更和軟體升級 (請參閱第 25.6.5 節 「執行 NDB Cluster 的滾動重新啟動」)。滾動重新啟動也用作將新資料節點線上新增的流程的一部分 (請參閱第 25.6.7 節 「線上新增 NDB Cluster 資料節點」)。如需資料節點、它們在 NDB Cluster 中的組織方式,以及它們如何處理和儲存 NDB Cluster 資料的詳細資訊,請參閱第 25.2.2 節 「NDB Cluster 節點、節點群組、片段複本與分割區」。
可以使用 NDB Cluster 管理用戶端中的 NDB 原生功能和 NDB Cluster 發行版本中包含的 ndb_restore 程式來備份和還原 NDB Cluster 資料庫。如需詳細資訊,請參閱第 25.6.8 節 「NDB Cluster 的線上備份」,以及第 25.5.23 節 「ndb_restore — 還原 NDB Cluster 備份」。您也可以使用 mysqldump 和 MySQL 伺服器中為此目的提供的標準 MySQL 功能。如需詳細資訊,請參閱第 6.5.4 節 「mysqldump — 資料庫備份程式」。
NDB Cluster 節點可以使用不同的傳輸機制進行節點間通訊;在大多數實際部署中,會使用透過標準 100 Mbps 或更快速的乙太網路硬體的 TCP/IP。