MySQL 8.4 版本資訊
在兩個叢集之間使用 NDB Cluster 進行雙向複寫,以及在任意數量的叢集之間進行循環複寫是可行的。
循環複寫範例。在接下來的幾個段落中,我們將考慮一個涉及三個 NDB Cluster(編號為 1、2 和 3)的複寫設定範例,其中 Cluster 1 作為 Cluster 2 的複寫來源,Cluster 2 作為 Cluster 3 的來源,而 Cluster 3 作為 Cluster 1 的來源。每個叢集都有兩個 SQL 節點,其中 SQL 節點 A 和 B 屬於 Cluster 1,SQL 節點 C 和 D 屬於 Cluster 2,而 SQL 節點 E 和 F 屬於 Cluster 3。
只要滿足以下條件,就支援使用這些叢集的循環複寫:
所有來源和複本上的 SQL 節點都相同。
所有作為來源和複本的 SQL 節點都已啟用系統變數
log_replica_updates來啟動。
此類型的循環複寫設定如下圖所示:
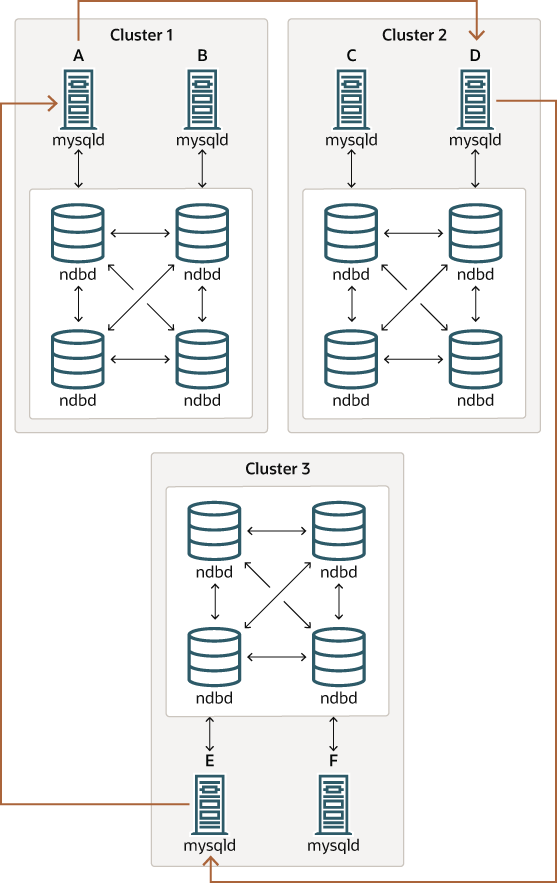
在此情境中,Cluster 1 中的 SQL 節點 A 複寫到 Cluster 2 中的 SQL 節點 C;SQL 節點 C 複寫到 Cluster 3 中的 SQL 節點 E;SQL 節點 E 複寫到 SQL 節點 A。換句話說,複寫線(圖中彎曲箭頭指示)直接連接所有用作複寫來源和複本的 SQL 節點。
也可以設定循環複寫,讓並非所有來源 SQL 節點都是複本,如下所示:
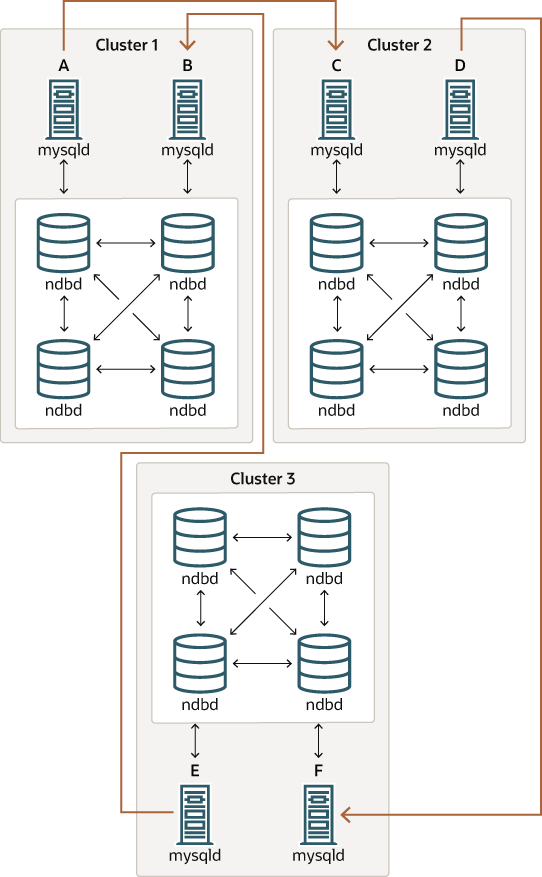
在這種情況下,每個叢集中不同的 SQL 節點用作複寫來源和複本。您不 得在啟用了系統變數 log_replica_updates 的情況下啟動任何 SQL 節點。對於 NDB Cluster,這種複寫線(同樣由圖中的彎曲箭頭指示)不連續的循環複寫配置應是可行的,但應注意,它尚未經過徹底測試,因此仍應視為實驗性質。
使用 NDB 原生備份和還原初始化複本叢集。 設定循環複寫時,可以使用管理用戶端 START BACKUP 命令在一個 NDB Cluster 上建立備份,然後使用 ndb_restore 將此備份應用於另一個 NDB Cluster 來初始化複本叢集。這不會在作為複本的第二個 NDB Cluster 的 SQL 節點上自動建立二進位日誌;為了建立二進位日誌,您必須在該 SQL 節點上發出 SHOW TABLES 陳述式;這應在執行 START REPLICA 之前完成。這是一個已知問題。
多來源容錯移轉範例。在本節中,我們將討論具有伺服器 ID 1、2 和 3 的三個 NDB Cluster 的多來源 NDB Cluster 複寫設定中的容錯移轉。在此情境中,Cluster 1 複寫到 Cluster 2 和 3;Cluster 2 也複寫到 Cluster 3。此關係如下所示:
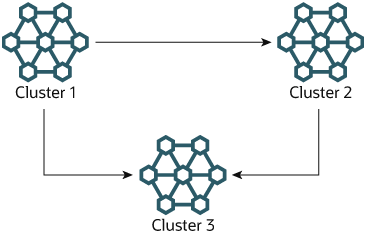
換句話說,資料透過 2 種不同的路由從 Cluster 1 複寫到 Cluster 3:直接複寫和透過 Cluster 2 複寫。
並非所有參與多來源複寫的 MySQL 伺服器都必須同時作為來源和複本,並且指定的 NDB Cluster 可能對不同的複寫通道使用不同的 SQL 節點。這種情況如下所示:
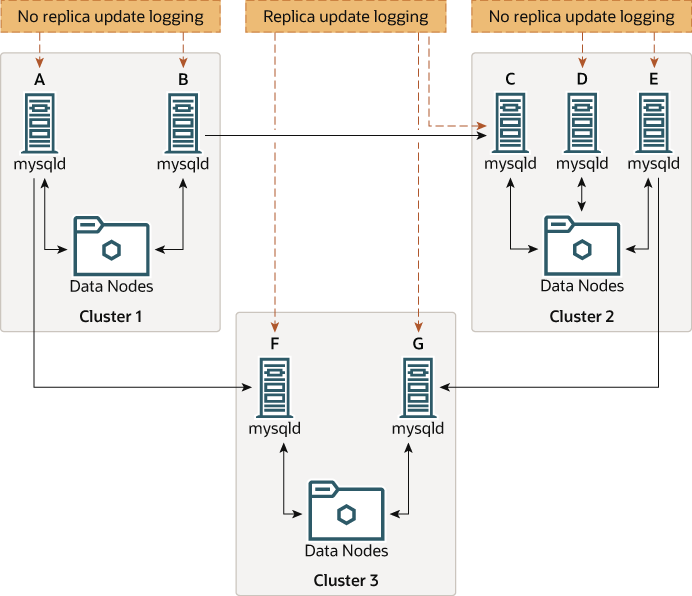
作為複本的 MySQL 伺服器必須在啟用了系統變數 log_replica_updates 的情況下執行。前述圖中也顯示了哪些 mysqld 程序需要此選項。
注意
使用 log_replica_updates 系統變數對未作為複本執行的伺服器沒有影響。
當其中一個複寫叢集關閉時,會產生容錯移轉的需求。在此範例中,我們考慮 Cluster 1 停止服務的情況,因此 Cluster 3 會失去來自 Cluster 1 的 2 個更新來源。由於 NDB Cluster 之間的複寫是異步的,因此無法保證 Cluster 3 直接來自 Cluster 1 的更新比透過 Cluster 2 接收到的更新更新。您可以確保 Cluster 3 在來自 Cluster 1 的更新方面趕上 Cluster 2 來處理此情況。就 MySQL 伺服器而言,這表示您需要將 MySQL 伺服器 C 中任何未完成的更新複寫到伺服器 F。
在伺服器 C 上,執行以下查詢:
mysqlC> SELECT @latest:=MAX(epoch)
-> FROM mysql.ndb_apply_status
-> WHERE server_id=1;
mysqlC> SELECT
-> @file:=SUBSTRING_INDEX(File, '/', -1),
-> @pos:=Position
-> FROM mysql.ndb_binlog_index
-> WHERE orig_epoch >= @latest
-> AND orig_server_id = 1
-> ORDER BY epoch ASC LIMIT 1;注意
您可以透過將適當的索引新增至 ndb_binlog_index 資料表來改善此查詢的效能,從而可能顯著加快容錯移轉時間。如需更多資訊,請參閱 第 25.7.4 節「NDB Cluster 複寫架構和資料表」。
手動將 @file 和 @pos 的值從伺服器 C 複製到伺服器 F(或讓您的應用程式執行等效的操作)。然後,在伺服器 F 上,執行以下 CHANGE REPLICATION SOURCE TO 陳述式:
mysqlF> CHANGE REPLICATION SOURCE TO
-> SOURCE_HOST = 'serverC'
-> SOURCE_LOG_FILE='@file',
-> SOURCE_LOG_POS=@pos;完成此操作後,您可以在 MySQL 伺服器 F 上發出 START REPLICA 陳述式;這會將任何來自伺服器 B 的遺失更新複寫到伺服器 F。
CHANGE REPLICATION SOURCE TO 陳述式還支援 IGNORE_SERVER_IDS 選項,該選項接受逗號分隔的伺服器 ID 清單,並導致忽略來自相應伺服器的事件。如需更多資訊,請參閱此陳述式的說明文件,以及 第 15.7.7.34 節「SHOW REPLICA STATUS 陳述式」。如需有關此選項如何與 ndb_log_apply_status 變數互動的資訊,請參閱 第 25.7.8 節「使用 NDB Cluster 複寫實作容錯移轉」。