MySQL 8.4 版本注意事項
NDB 叢集中的複寫會使用多個專用資料表,這些資料表位於作為叢集中 SQL 節點的每個 MySQL Server 執行個體的 mysql 資料庫中,無論是在複寫的叢集中還是在複本中都如此。無論複本是單一伺服器或叢集,皆是如此。
ndb_binlog_index 和 ndb_apply_status 資料表是在 mysql 資料庫中建立的。使用者不應明確地複寫這些資料表。通常不需要使用者介入來建立或維護這兩個資料表,因為這兩個資料表都由 NDB 二進位記錄 (binlog) 注入器執行緒維護。這會讓來源 mysqld 程序與 NDB 儲存引擎執行的變更保持同步。NDB binlog 注入器執行緒直接從 NDB 儲存引擎接收事件。NDB 注入器負責擷取叢集內的所有資料事件,並確保將變更、插入或刪除資料的所有事件都記錄在 ndb_binlog_index 資料表中。複本 I/O (接收器) 執行緒會將事件從來源的二進位記錄檔傳輸到複本的轉送記錄檔。
ndb_replication 資料表必須手動建立。使用者可以更新此資料表,以依資料庫或資料表執行篩選。如需更多資訊,請參閱 ndb_replication 資料表。ndb_replication 也用於 NDB 複寫衝突偵測和衝突解決的衝突解決控制;請參閱 衝突解決控制。
即使 ndb_binlog_index 和 ndb_apply_status 是自動建立和維護的,建議在準備 NDB 叢集進行複寫時,檢查這些資料表是否存在以及是否完整。可以透過直接在來源上查詢 mysql.ndb_binlog_index 資料表來檢視二進位記錄檔中記錄的事件資料。也可以在來源或複本 SQL 節點上使用 SHOW BINLOG EVENTS 陳述式來達成此目的。(請參閱 第 15.7.7.3 節,「SHOW BINLOG EVENTS 陳述式」。)
您也可以從 SHOW ENGINE NDB STATUS 的輸出中取得實用資訊。
注意
當在 NDB 資料表上執行架構變更時,應用程式應等到發出陳述式的 MySQL 用戶端連線中的 ALTER TABLE 陳述式傳回後,才嘗試使用資料表的更新定義。
ndb_apply_status 用於記錄已從來源複寫到複本的操作。如果複本上不存在 ndb_apply_status 資料表,ndb_restore 會重新建立此資料表。
與 ndb_binlog_index 的情況不同,此資料表中的資料並非特定於 (複本) 叢集中的任何一個 SQL 節點,因此 ndb_apply_status 可以使用 NDBCLUSTER 儲存引擎,如下所示
CREATE TABLE `ndb_apply_status` (
`server_id` INT(10) UNSIGNED NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`log_name` VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`start_pos` BIGINT(20) UNSIGNED NOT NULL,
`end_pos` BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (`server_id`) USING HASH
) ENGINE=NDBCLUSTER DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;ndb_apply_status 資料表僅在複本上填入,這表示在來源上,此資料表永遠不會包含任何列;因此,不需要在那裡配置任何 DataMemory 給 ndb_apply_status。
由於此資料表是從來源上的資料填入的,因此應允許複寫;任何無意中阻止複本更新 ndb_apply_status 或阻止來源寫入二進位記錄檔的複寫篩選或二進位記錄篩選規則,都可能會阻止叢集之間的複寫正常運作。如需更多有關此類篩選規則可能產生的問題資訊,請參閱 NDB 叢集之間複寫的複寫和二進位記錄篩選規則。
可以刪除此資料表,但不建議這麼做。刪除此資料表會將所有 SQL 節點設為唯讀模式;NDB 會偵測到此資料表已刪除,並重新建立,之後就可以再次執行更新。刪除和重新建立 ndb_apply_status 會在二進位記錄檔中建立間隙事件;間隙事件會導致複本 SQL 節點停止套用來自來源的變更,直到重新啟動複寫通道為止。
此資料表的 epoch 資料欄中的 0 表示來源為 NDB 以外的儲存引擎的交易。
ndb_apply_status 用於記錄已從上游來源複寫並套用至複本叢集的 epoch 交易。此資訊會擷取在 NDB 線上備份中,但 (依設計) 不會由 ndb_restore 還原。在某些情況下,還原此資訊以便在新設定中使用可能會很有幫助;您可以透過使用 --with-apply-status 選項叫用 ndb_restore 來達成此目的。如需更多資訊,請參閱選項的描述。
NDB 叢集複寫使用 ndb_binlog_index 資料表來儲存二進位記錄檔的索引資料。由於此資料表是每個 MySQL 伺服器的本機資料表,且未參與叢集,因此使用 InnoDB 儲存引擎。這表示必須在參與來源叢集的每個 mysqld 上分別建立此資料表。(二進位記錄檔本身包含來自叢集中所有 MySQL 伺服器的更新。) 此資料表的定義如下
CREATE TABLE `ndb_binlog_index` (
`Position` BIGINT(20) UNSIGNED NOT NULL,
`File` VARCHAR(255) NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`inserts` INT(10) UNSIGNED NOT NULL,
`updates` INT(10) UNSIGNED NOT NULL,
`deletes` INT(10) UNSIGNED NOT NULL,
`schemaops` INT(10) UNSIGNED NOT NULL,
`orig_server_id` INT(10) UNSIGNED NOT NULL,
`orig_epoch` BIGINT(20) UNSIGNED NOT NULL,
`gci` INT(10) UNSIGNED NOT NULL,
`next_position` bigint(20) unsigned NOT NULL,
`next_file` varchar(255) NOT NULL,
PRIMARY KEY (`epoch`,`orig_server_id`,`orig_epoch`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;注意
如果您是從舊版本升級,請執行 MySQL 升級程序,並確保透過使用 --upgrade=FORCE 選項啟動 MySQL 伺服器來升級系統表。系統表升級會導致針對此表執行 ALTER TABLE ... ENGINE=INNODB 語句。為了向後兼容,仍然支援對此表使用 MyISAM 儲存引擎。
轉換為 InnoDB 後,ndb_binlog_index 可能需要額外的磁碟空間。如果這成為一個問題,您可以使用此表的 InnoDB 表空間、將其 ROW_FORMAT 變更為 COMPRESSED,或兩者兼施,來節省空間。如需更多資訊,請參閱 章節 15.1.21,「CREATE TABLESPACE 語句」,和 章節 15.1.20,「CREATE TABLE 語句」,以及 章節 17.6.3,「表空間」。
ndb_binlog_index 表的大小取決於每個二進制日誌檔案的週期數和二進制日誌檔案的數量。每個二進制日誌檔案的週期數通常取決於每個週期產生的二進制日誌數量和二進制日誌檔案的大小,較小的週期會導致每個檔案有更多週期。您應該注意到,即使 --ndb-log-empty-epochs 選項為 OFF 時,空的週期也會產生對 ndb_binlog_index 表的插入操作,這表示每個檔案的條目數量取決於該檔案的使用時間長度;此關係可以用這裡顯示的公式表示
[number of epochs per file] = [time spent per file] / TimeBetweenEpochs忙碌的 NDB Cluster 會定期寫入二進制日誌,並且可能比閒置的叢集更快輪換二進制日誌檔案。這表示啟用 --ndb-log-empty-epochs=ON 的「閒置」NDB Cluster 實際上可能比有大量活動的叢集擁有更高的每個檔案 ndb_binlog_index 行數。
當使用 --ndb-log-orig 選項啟動 mysqld 時,orig_server_id 和 orig_epoch 欄分別儲存事件發生的伺服器 ID 以及事件在原始伺服器上發生的週期,這在採用多個來源的 NDB Cluster 複寫設定中非常有用。用於在多來源設定中尋找最接近複本上已應用最高週期的二進制日誌位置的 SELECT 語句(請參閱 章節 25.7.10,「NDB Cluster 複寫:雙向和循環複寫」)使用這兩個未編入索引的欄位。這可能會在嘗試故障轉移時導致效能問題,因為查詢必須執行表掃描,尤其是在來源使用 --ndb-log-empty-epochs=ON 執行的情況下。您可以透過將索引新增至這些欄位來改善多來源故障轉移時間,如下所示
ALTER TABLE mysql.ndb_binlog_index
ADD INDEX orig_lookup USING BTREE (orig_server_id, orig_epoch);從單一來源複寫到單一複本時,新增此索引沒有任何好處,因為在這種情況下,用於取得二進制日誌位置的查詢不會使用 orig_server_id 或 orig_epoch。
如需更多有關使用 next_position 和 next_file 欄位的資訊,請參閱 章節 25.7.8,「使用 NDB Cluster 複寫實作故障轉移」。
下圖顯示 NDB Cluster 複寫來源伺服器、其二進制日誌注入器執行緒和 mysql.ndb_binlog_index 表的關係。
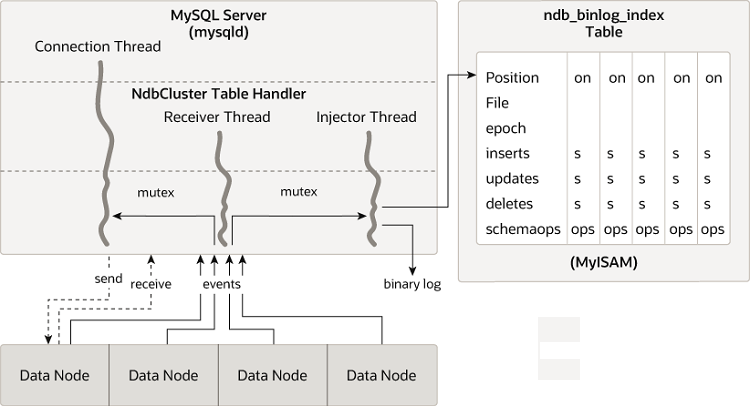
ndb_replication 表用於控制二進制日誌和衝突解決,並針對每個表執行。此表中的每一列都對應於正在複寫的表,決定如何記錄對該表的變更,如果指定了衝突解決函數,則決定如何解決該表的衝突。
與 ndb_apply_status 和 ndb_replication 表不同,ndb_replication 表必須使用此處顯示的 SQL 語句手動建立
CREATE TABLE mysql.ndb_replication (
db VARBINARY(63),
table_name VARBINARY(63),
server_id INT UNSIGNED,
binlog_type INT UNSIGNED,
conflict_fn VARBINARY(128),
PRIMARY KEY USING HASH (db, table_name, server_id)
) ENGINE=NDB
PARTITION BY KEY(db,table_name);此表的欄位會列在這裡,並附有說明
db欄位包含要複寫之表的資料庫名稱。
您可以採用萬用字元
_和%的其中之一或兩者作為資料庫名稱的一部分。(請參閱本節稍後的 使用萬用字元進行比對。)table_name欄位要複寫的表名稱。
表名稱可以包含萬用字元
_和%的其中之一或兩者。請參閱本節稍後的 使用萬用字元進行比對。server_id欄位表所在的 MySQL 實例 (SQL 節點) 的唯一伺服器 ID。
此欄位中的
0的作用類似於%的萬用字元,並且符合任何伺服器 ID。(請參閱本節稍後的 使用萬用字元進行比對。)binlog_type欄位要使用的二進制日誌類型。請參閱文字以取得值和說明。
conflict_fn欄位要套用的衝突解決函數;NDB$OLD()、NDB$MAX()、NDB$MAX_DELETE_WIN()、NDB$EPOCH()、NDB$EPOCH_TRANS()、NDB$EPOCH2()、NDB$EPOCH2_TRANS() NDB$MAX_INS() 或 NDB$MAX_DEL_WIN_INS() 其中之一;
NULL表示此表未使用衝突解決。如需更多關於這些函數及其在 NDB 複寫衝突解決中的使用的資訊,請參閱衝突解決函數。
某些衝突解決函數 (
NDB$OLD()、NDB$EPOCH()、NDB$EPOCH_TRANS()) 需要使用一或多個使用者建立的例外表。請參閱 衝突解決例外表。
若要使用 NDB 複寫啟用衝突解決,必須在應該解決衝突的 SQL 節點上建立並填入此表,其中包含控制資訊。根據要採用的衝突解決類型和方法,這可能是來源、複本或兩者伺服器。在複本也可以在本地變更資料的簡單來源-複本設定中,這通常是複本。在更複雜的複寫方案(例如雙向複寫)中,這通常是所有相關來源。如需更多資訊,請參閱 章節 25.7.12,「NDB Cluster 複寫衝突解決」。
ndb_replication 表允許在衝突解決範圍之外針對二進制日誌進行表級控制,在這種情況下,conflict_fn 會指定為 NULL,而其餘欄位值則是用於控制指定表或符合萬用字元運算式的一組表的二進制日誌。透過為 binlog_type 欄位設定正確的值,您可以使指定表或數個表的記錄使用所需的二進制日誌格式,或完全停用二進制日誌。此欄位的可能值及其說明顯示在下表中
表 25.42 binlog_type 值及其說明
| 值 | 說明 |
|---|---|
| 0 | 使用伺服器預設值 |
| 1 | 請勿在二進制日誌中記錄此表 (與 sql_log_bin = 0 的效果相同,但僅適用於一或多個指定的表) |
| 2 | 僅記錄更新的屬性;將這些記錄為 WRITE_ROW 事件 |
| 3 | 記錄完整列,即使未更新 (MySQL 伺服器預設行為) |
| 6 | 使用更新的屬性,即使值未變更 |
| 7 | 記錄完整列,即使沒有值變更;將更新記錄為 UPDATE_ROW 事件 |
| 8 | 將更新記錄為 UPDATE_ROW;僅記錄之前映像中的主索引鍵欄位,以及之後映像中僅記錄更新的欄位 (與 --ndb-log-update-minimal 的效果相同,但僅適用於一或多個指定的表) |
| 9 | 將更新記錄為 UPDATE_ROW;僅記錄之前映像中的主索引鍵欄位,以及之後映像中主索引鍵欄位以外的所有欄位 |
注意
binlog_type 值 4 和 5 未使用,因此從剛才顯示的表以及下一個表中省略。
數個 binlog_type 值等同於 mysqld 記錄選項 --ndb-log-updated-only、--ndb-log-update-as-write 和 --ndb-log-update-minimal 的各種組合,如下表所示
表 25.43:binlog_type 值與 NDB 記錄選項的等效組合
| 值 | --ndb-log-updated-only 值 |
--ndb-log-update-as-write 值 |
--ndb-log-update-minimal 值 |
|---|---|---|---|
| 0 | -- | -- | -- |
| 1 | -- | -- | -- |
| 2 | 啟用 (ON) | 啟用 (ON) | 停用 (OFF) |
| 3 | 停用 (OFF) | 啟用 (ON) | 停用 (OFF) |
| 6 | 啟用 (ON) | 停用 (OFF) | 停用 (OFF) |
| 7 | 停用 (OFF) | 停用 (OFF) | 停用 (OFF) |
| 8 | 啟用 (ON) | 停用 (OFF) | 啟用 (ON) |
| 9 | 停用 (OFF) | 停用 (OFF) | 啟用 (ON) |
透過將資料列插入 ndb_replication 資料表,並使用適當的 db、table_name 和 binlog_type 欄位值,可以針對不同的資料表設定不同的二進制日誌格式。設定二進制日誌格式時,應使用上表所示的內部整數值。以下兩個陳述式將資料表 test.a 的二進制日誌設定為記錄完整資料列(值為 3),並將資料表 test.b 的二進制日誌設定為僅記錄更新(值為 2):
# Table test.a: Log full rows
INSERT INTO mysql.ndb_replication VALUES("test", "a", 0, 3, NULL);
# Table test.b: log updates only
INSERT INTO mysql.ndb_replication VALUES("test", "b", 0, 2, NULL);若要停用一個或多個資料表的記錄,請使用 binlog_type 的值 1,如下所示:
# Disable binary logging for table test.t1
INSERT INTO mysql.ndb_replication VALUES("test", "t1", 0, 1, NULL);
# Disable binary logging for any table in 'test' whose name begins with 't'
INSERT INTO mysql.ndb_replication VALUES("test", "t%", 0, 1, NULL);停用特定資料表的記錄等同於設定 sql_log_bin = 0,只是它會個別套用至一個或多個資料表。如果 SQL 節點沒有針對特定資料表執行二進制日誌記錄,則不會將這些資料表的資料列變更事件傳送給它。這表示它並非接收所有變更然後丟棄部分變更,而是未訂閱這些變更。
停用記錄在許多情況下都很有用,包括以下列出的原因:
通常,不透過網路傳送變更可以節省頻寬、緩衝和 CPU 資源。
不記錄頻繁更新但價值不高的資料表變更很適合用於臨時資料(例如工作階段資料),這些資料在叢集完全故障時可能相對不重要。
使用工作階段變數(或
sql_log_bin)和應用程式碼,也可以記錄(或不記錄)某些 SQL 陳述式或 SQL 陳述式類型;例如,在某些情況下,可能不希望記錄一個或多個資料表的 DDL 陳述式。將複寫串流分割為兩個(或多個)二進制日誌,可能是因為效能考量、需要將不同資料庫複寫到不同位置,或是針對不同資料庫使用不同的二進制記錄類型等等原因。
使用萬用字元比對。為了避免需要在複寫設定中針對資料庫、資料表和 SQL 節點的每個組合都在 ndb_replication 資料表中插入資料列,NDB 支援在此資料表的 db、table_name 和 server_id 欄位上進行萬用字元比對。在 db 和 table_name 中使用的資料庫和資料表名稱可能包含以下一或多個萬用字元:
_(底線字元):比對零或多個字元%(百分比符號):比對單一字元
(這些是 MySQL LIKE 運算子支援的相同萬用字元。)
server_id 欄位支援使用 0 作為萬用字元,等同於 _(比對任何字元)。這已在先前顯示的範例中使用。
ndb_replication 資料表中的指定資料列可以使用萬用字元,比對資料庫名稱、資料表名稱和伺服器 ID 的任意組合。如果資料表中有多個潛在的比對,則會選擇最佳比對,如下表所示,其中 W 代表萬用字元比對,E 代表完全比對,Quality 欄位中的值越高,比對效果越好
表 25.44:mysql.ndb_replication 資料表中萬用字元和完全比對的不同組合的權重
db |
table_name |
server_id |
品質 (Quality) |
|---|---|---|---|
| W | W | W | 1 |
| W | W | E | 2 |
| W | E | W | 3 |
| W | E | E | 4 |
| E | W | W | 5 |
| E | W | E | 6 |
| E | E | W | 7 |
| E | E | E | 8 |
因此,完全比對資料庫名稱、資料表名稱和伺服器 ID 會被視為最佳(最強),而最弱(最差)的比對是所有三個欄位都使用萬用字元比對。選擇要套用的規則時,僅考慮比對的強度;資料列在資料表中出現的順序對此判斷沒有影響。
記錄完整或部分資料列。 根據 mysqld 的 --ndb-log-updated-only 選項設定,記錄資料列有兩種基本方法:
記錄完整資料列(選項設定為
ON)僅記錄已更新的欄位資料,也就是已設定值的欄位資料,無論此值是否實際變更。這是預設行為(選項設定為
OFF)。
通常,僅記錄已更新的欄位就足夠且更有效率;但是,如果您需要記錄完整資料列,可以將 --ndb-log-updated-only 設定為 0 或 OFF 來達成。
將變更的資料記錄為更新。 MySQL 伺服器的 --ndb-log-update-as-write 選項設定決定記錄是否在有或沒有「之前」影像的情況下執行。
由於更新和刪除作業的衝突解決是在 MySQL 伺服器的更新處理常式中完成,因此必須控制複寫來源執行的記錄,使更新是更新而不是寫入;也就是說,使更新被視為現有資料列的變更,而不是寫入新的資料列,即使這些資料列會取代現有的資料列。
預設會開啟此選項;換句話說,更新會被視為寫入。也就是說,預設會將更新以二進制日誌中的 write_row 事件寫入,而不是 update_row 事件。
若要停用此選項,請使用 --ndb-log-update-as-write=0 或 --ndb-log-update-as-write=OFF 啟動來源 mysqld。當從 NDB 資料表複寫到使用不同儲存引擎的資料表時,必須執行此操作;請參閱從 NDB 複寫到其他儲存引擎,以及從 NDB 複寫到非交易式儲存引擎,以取得更多資訊。
重要
對於使用 NDB$MAX_INS() 或 NDB$MAX_DEL_WIN_INS() 的插入衝突解決方案,SQL 節點(也就是 mysqld 程序)可以記錄來源叢集上的資料列更新作為 WRITE_ROW 事件,並啟用 --ndb-log-update-as-write 選項,以確保等冪性並達到最佳大小。這些演算法之所以能運作,是因為它們都會將 WRITE_ROW 事件對應至插入或更新,具體取決於資料列是否已存在,且必要的元資料(時間戳記欄位的「之後」影像)存在於「WRITE_ROW」事件中。