MySQL 8.4 發行說明
本節討論 NDB Cluster 如何分割和複製資料以進行儲存。
接下來的幾個段落將討論理解本主題的一些核心概念。
資料節點。 ndbd 或 ndbmtd 程序,其儲存一個或多個片段副本—也就是指,指派給節點所屬節點群組的分割區副本 (本節稍後討論)。
每個資料節點都應該位於不同的電腦上。雖然也可以在單一電腦上託管多個資料節點程序,但通常不建議這樣設定。
當提到 ndbd 或 ndbmtd 程序時,「節點」和「資料節點」這兩個術語通常可以互換使用;在提及管理節點 (ndb_mgmd 程序) 和 SQL 節點 (mysqld 程序) 時,會在本次討論中加以明確指出。
節點群組。 節點群組由一個或多個節點組成,並儲存分割區或片段副本集合 (請參閱下一項)。
NDB Cluster 中的節點群組數量無法直接設定;它是資料節點數量和片段副本數量 (NoOfReplicas 組態參數) 的函數,如下所示
[# of node groups] = [# of data nodes] / NoOfReplicas因此,若在 config.ini 檔案中,將 NoOfReplicas 設為 1,則具有 4 個資料節點的 NDB Cluster 將有 4 個節點群組;若設為 2,則有 2 個節點群組;若設為 4,則有 1 個節點群組。片段副本將在本節稍後討論;如需有關 NoOfReplicas 的詳細資訊,請參閱第 25.4.3.6 節,「定義 NDB Cluster 資料節點」。
注意
NDB Cluster 中的所有節點群組都必須具有相同數量的資料節點。
您可以線上將新的節點群組 (以及新的資料節點) 新增到正在執行的 NDB Cluster;如需詳細資訊,請參閱第 25.6.7 節,「線上新增 NDB Cluster 資料節點」。
分割區。 這是叢集儲存資料的一部分。每個節點負責保留至少一個指派給它的任何分割區副本 (即至少一個片段副本),以便叢集使用。
NDB Cluster 預設使用的分割區數量取決於資料節點的數量以及資料節點使用的 LDM 執行緒數量,如下所示
[# of partitions] = [# of data nodes] * [# of LDM threads]使用執行 ndbmtd 的資料節點時,LDM 執行緒數量由 MaxNoOfExecutionThreads 的設定控制。使用 ndbd 時,會有單一 LDM 執行緒,這表示叢集分割區的數量與參與叢集的節點數量相同。當使用 ndbmtd 且 MaxNoOfExecutionThreads 設定為 3 或更小時,也會發生這種情況。(您應該知道 LDM 執行緒的數量會隨著此參數的值而增加,但並非嚴格線性增加,而且設定它時還有其他限制;如需詳細資訊,請參閱 MaxNoOfExecutionThreads 的說明。)
NDB 和使用者定義的分割區。 NDB Cluster 通常會自動分割 NDBCLUSTER 表格。不過,也可以在 NDBCLUSTER 表格上採用使用者定義的分割區。這受到以下限制
在
NDB表格的生產環境中,僅支援KEY和LINEAR KEY分割區配置。針對任何
NDB表格明確定義的最大分割區數量為8 * [,NDB Cluster 中的節點群組數量已如本節先前所述決定。針對資料節點程序執行 ndbd 時,設定 LDM 執行緒的數量沒有作用 (因為LDM 執行緒數量] * [節點群組數量]ThreadConfig僅適用於 ndbmtd);在這種情況下,為了執行此計算,可以將此值視為等於 1。如需詳細資訊,請參閱第 25.5.3 節,「ndbmtd — NDB Cluster 資料節點常駐程式 (多執行緒)」。
如需有關 NDB Cluster 和使用者定義分割區的詳細資訊,請參閱第 25.2.7 節,「NDB Cluster 的已知限制」,以及第 26.6.2 節,「與儲存引擎相關的分割區限制」。
片段副本。 這是叢集分割區的副本。節點群組中的每個節點都會儲存一個片段副本。也稱為分割區副本。片段副本的數量等於每個節點群組的節點數量。
片段副本完全屬於單一節點;節點可以 (而且通常會) 儲存多個片段副本。
下圖說明一個具有四個執行 ndbd 之資料節點的 NDB Cluster,這些資料節點排列成兩個節點群組,每個群組有兩個節點;節點 1 和 2 屬於節點群組 0,而節點 3 和 4 屬於節點群組 1。
注意
這裡只顯示資料節點;雖然運作的 NDB Cluster 需要一個用於叢集管理的 ndb_mgmd 程序,以及至少一個 SQL 節點來存取叢集儲存的資料,但為了清楚起見,已從圖中省略這些程序。
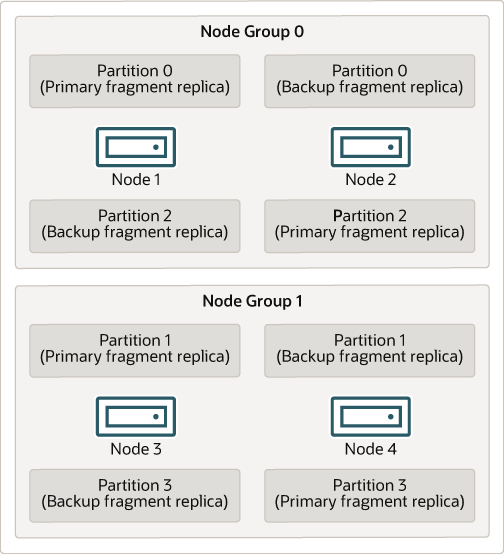
叢集儲存的資料會分成四個分割區,編號為 0、1、2 和 3。每個分割區都以多個副本的形式儲存在相同的節點群組上。分割區會依如下方式儲存在替代的節點群組上
分割區 0 儲存在節點群組 0 上;主要片段副本 (主要副本) 儲存在節點 1 上,而備份片段副本 (分割區的備份副本) 儲存在節點 2 上。
分割區 1 儲存在另一個節點群組上 (節點群組 1);此分割區的主要片段副本位於節點 3 上,而其備份片段副本位於節點 4 上。
分割區 2 儲存在節點群組 0 上。但是,其兩個片段副本的放置位置與分割區 0 的位置相反;對於分割區 2,主要片段副本儲存在節點 2 上,而備份副本儲存在節點 1 上。
分割區 3 儲存在節點群組 1 上,且其兩個片段副本的放置位置與分割區 1 的位置相反。也就是說,其主要片段副本位於節點 4 上,而備份副本位於節點 3 上。
這對於 NDB Cluster 的持續運作而言,表示:只要叢集中參與的每個節點群組至少有一個節點運作,叢集就具有所有資料的完整副本,且仍可運作。下圖說明了這一點。
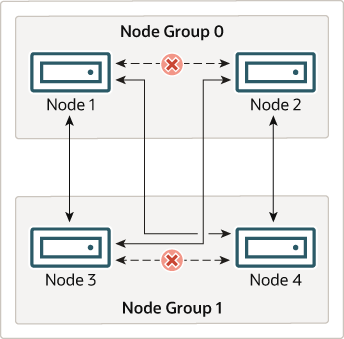
在本範例中,叢集包含兩個節點群組,每個群組由兩個資料節點組成。每個資料節點都執行 ndbd 的執行個體。只要節點群組 0 中至少有一個節點,且節點群組 1 中至少有一個節點的任何組合,就足以保持叢集「運作」。但是,如果單一節點群組中的兩個節點都失敗,則由另一個節點群組中其餘兩個節點組成的組合便不足以保持叢集運作。在這種情況下,叢集已遺失整個分割區,因此無法再提供對所有 NDB Cluster 資料完整集合的存取權。
單一 NDB Cluster 執行個體支援的最大節點群組數量為 48 個。