PDF (美式信紙) - 2.2Mb
PDF (A4) - 2.3Mb
緊急故障轉移會將選定的複本叢集變成 InnoDB ClusterSet 部署的主要 InnoDB 叢集。當目前的主要叢集無法運作或無法連線時,可以使用此程序。在緊急故障轉移過程中,無法保證資料一致性,因此為了安全起見,原始主要叢集會在故障轉移過程中標示為失效。如果原始主要叢集保持在線上,則應在可以連線時盡快關閉。您可以在解決問題後修復失效的原始主要叢集並將其重新加入 InnoDB ClusterSet 拓撲。
當 InnoDB ClusterSet 部署中的主要 InnoDB 叢集發生問題或您無法存取時,請勿立即對複本叢集實施緊急故障轉移。相反地,您應該始終先嘗試修復目前活動的主要叢集。
重要
為何不直接故障轉移? InnoDB ClusterSet 拓撲中的複本叢集會盡力與主要叢集保持同步。但是,根據交易量以及主要叢集和複本叢集之間的網路連線速度和容量,複本叢集在接收交易並將變更套用至其資料時可能會落後於主要叢集。這稱為複製延遲。在大多數複製拓撲中,預期會有一些複製延遲,而且在叢集地理分散且位於不同資料中心的 InnoDB ClusterSet 部署中,很可能會發生這種情況。
此外,主要叢集可能會因為網路分割而與 InnoDB ClusterSet 拓撲的其他元素斷開連線,但仍保持在線上。如果發生這種情況,某些複本叢集可能會與主要叢集保持連線,而某些執行個體和用戶端應用程式可能會繼續連線至主要叢集並套用交易。在這種情況下,InnoDB ClusterSet 拓撲的分割區域開始彼此分歧,每組伺服器上的交易集都不同。
當出現複製延遲或網路分割時,如果您觸發對複本叢集的緊急故障轉移,主要叢集上的任何未複製或分歧的交易都有遺失的風險。在網路分割的情況下,故障轉移可能會造成腦裂情況,其中拓撲的不同部分具有分歧的交易集。因此,您應始終在觸發緊急故障轉移之前嘗試修復或重新連線主要叢集。如果無法快速修復或無法連線主要叢集,您可以繼續進行緊急故障轉移。
此圖顯示了在範例 InnoDB ClusterSet 部署中緊急故障轉移的效果。羅馬資料中心的主要叢集已離線,因此已執行緊急故障轉移,使布魯塞爾資料中心的複本叢集成為 InnoDB ClusterSet 部署的主要 InnoDB 叢集。羅馬叢集已標示為失效,其在 InnoDB ClusterSet 部署中的狀態已降級為複本叢集,儘管它目前無法從布魯塞爾叢集複製交易。
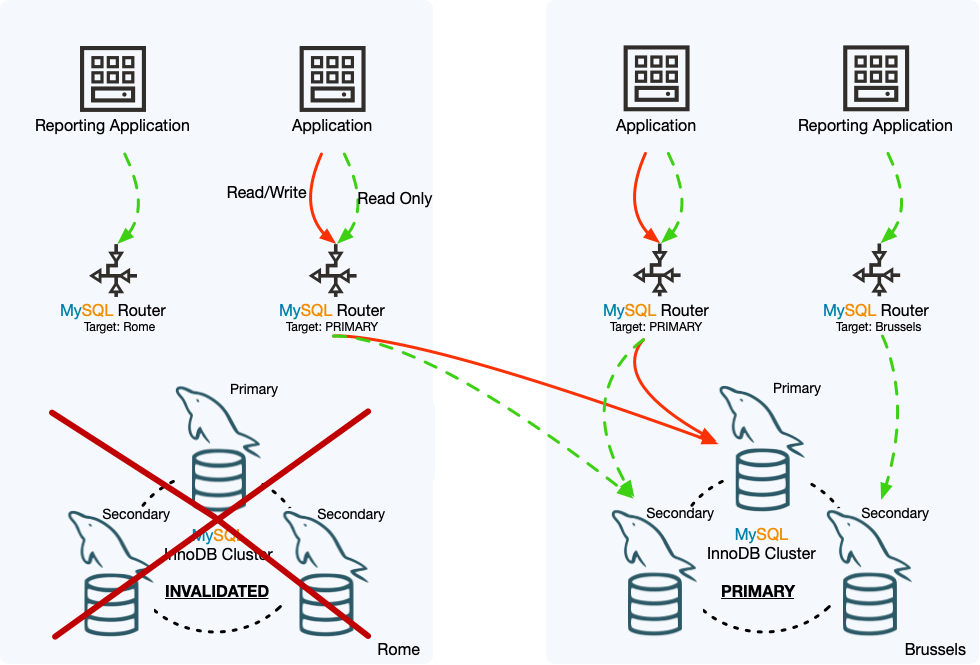
設定為追蹤主要叢集的 MySQL Router 執行個體已將讀取和寫入流量路由至現在是主要叢集的布魯塞爾叢集。當布魯塞爾叢集是複本叢集時,按名稱將讀取流量路由至該叢集的 MySQL Router 執行個體,會繼續將流量路由至該叢集,並且不受該叢集現在是主要叢集而不是複本叢集的事實影響。但是,按名稱將讀取流量路由至羅馬叢集的 MySQL Router 執行個體目前無法將任何流量傳送到該叢集。在此範例中,報告應用程式不需要在本地資料中心離線時進行報告,但如果應用程式仍需要運作,則應變更 MySQL Router 執行個體的路由選項,使其追蹤主要叢集或將流量傳送至布魯塞爾叢集。
若要對主要 InnoDB 叢集執行緊急故障轉移,請遵循此程序
-
使用 MySQL Shell,使用 InnoDB 叢集管理員帳戶(使用
cluster.setupAdminAccount()連線建立後,使用
dba.getClusterSet()或cluster.getClusterSet()ClusterSet物件。您先前從現在已離線的成員伺服器檢索的ClusterSet物件將無法再運作,因此您需要從線上的伺服器再次取得它。務必使用 InnoDB 叢集管理員帳戶或伺服器組態帳戶,以便儲存在ClusterSet物件中的預設使用者帳戶具有正確的權限。例如mysql-js> \connect admin2@127.0.0.1:4410 Creating a session to 'admin2@127.0.0.1:4410' Please provide the password for 'admin2@127.0.0.1:4410': ******** Save password for 'admin2@127.0.0.1:4410'? [Y]es/[N]o/Ne[v]er (default No): Fetching schema names for autocompletion... Press ^C to stop. Closing old connection... Your MySQL connection id is 71 Server version: 8.0.27-commercial MySQL Enterprise Server - Commercial No default schema selected; type \use <schema> to set one. <ClassicSession:admin2@127.0.0.1:4410> mysql-js> myclusterset = dba.getClusterSet() <ClusterSet:testclusterset> -
使用 MySQL Shell 中 AdminAPI 的
clusterSet.status()extended選項來查看問題的確切位置和原因。例如mysql-js> myclusterset.status({extended: 1})如需輸出的說明,請參閱 第 8.6 節,InnoDB ClusterSet 狀態和拓撲。
-
InnoDB 叢集可以容忍某些問題,並且可以正常運作,以繼續作為 InnoDB ClusterSet 部署的一部分。當您使用
clusterSet.status()OK。例如,如果叢集中的其中一個成員伺服器離線,即使該伺服器是主要的,基礎群組複製技術也可以處理這種情況並重新設定自身。如果主要叢集根據報告的狀態在 InnoDB ClusterSet 部署中仍可接受地運作,但您需要執行維護或修正一些小問題以改善主要叢集的功能,則可以執行對複本叢集的受控切換。然後,您可以視需要讓主要叢集離線,修復任何問題,並將其重新投入 InnoDB ClusterSet 部署中。如需執行此操作的指示,請參閱 第 8.7 節,InnoDB ClusterSet 受控切換。
如果主要叢集在 InnoDB ClusterSet 部署中無法接受地運作(全域狀態為
NOT_OK),但您可以連線至該叢集,請先嘗試使用 MySQL Shell 透過 AdminAPI 修復任何問題。例如,如果主要叢集失去法定人數,可以使用cluster.forceQuorumUsingPartitionOf-
如果您無法執行受控切換,並且無法透過使用主要叢集快速解決問題(例如,因為您無法連線至該叢集),請繼續進行緊急故障轉移。首先識別適合接管作為主要叢集的複本叢集。複本叢集是否符合緊急故障轉移的資格取決於其全域狀態,如
clusterSet.status()表 8.2 依狀態允許的叢集作業
InnoDB ClusterSet 中的 InnoDB 叢集全域狀態 可路由 受控切換 緊急容錯移轉 確定是 是 是 確定_未複製是,如果依名稱指定為目標叢集 是 是 確定_不一致是,如果依名稱指定為目標叢集 否 是 確定_設定錯誤是 是 是 不確定否 否 否 已失效是,如果依名稱指定為目標叢集,且設定了 accept_ro路由策略否 否 未知連線的路由器執行個體可能仍在將流量路由至叢集 否 否 您選取的複本叢集,必須在所有可連線的複本叢集中,擁有最新的一組交易 (GTID 集)。如果有多個複本叢集符合緊急容錯移轉的資格,請檢查每個叢集的複寫延遲(顯示在
clusterSet.status() -
藉由在連線至 InnoDB ClusterSet 部署中任何成員伺服器的 MySQL Shell 中,發出
clusterSet.routingOptions()mysql-js> myclusterset.routingOptions() { "domainName": "testclusterset", "global": { "invalidated_cluster_policy": "drop_all", "target_cluster": "primary" }, "routers": { "Rome1": { "target_cluster": "primary" }, "Rome2": {} } }如果所有 MySQL Router 執行個體都設定為追蹤主要叢集 (
"target_cluster": "primary"),則在容錯移轉後的幾秒內,流量將自動重新導向至新的主要叢集。如果沒有為 MySQL Router 執行個體顯示路由選項,例如上方範例中Rome2的"target_cluster",則表示執行個體沒有設定該策略,並會追蹤全域策略。如果任何執行個體設定為依名稱將目標設定為目前的主要叢集 (
"target_cluster": "),則它們不會將流量重新導向至新的主要叢集。當主要叢集無法運作時,無法使用主要叢集名稱"clusterSet.setRoutingOption() 如果可以,請嘗試驗證原始主要叢集是否離線,如果其在線上,請嘗試將其關閉。如果其保持在線上並持續接收來自用戶端的流量,則可能會建立腦裂狀況,導致 InnoDB ClusterSet 的分離部分出現差異。
-
若要繼續進行緊急容錯移轉,請發出
clusterSet.forcePrimaryCluster()mysql-js> myclusterset.forcePrimaryCluster("clustertwo") Failing-over primary cluster of the clusterset to 'clustertwo' * Verifying primary cluster status None of the instances of the PRIMARY cluster 'clusterone' could be reached. * Verifying clusterset status ** Checking cluster clustertwo Cluster 'clustertwo' is available ** Checking whether target cluster has the most recent GTID set * Promoting cluster 'clustertwo' * Updating metadata PRIMARY cluster failed-over to 'clustertwo'. The PRIMARY instance is '127.0.0.1:4410' Former PRIMARY cluster was INVALIDATED, transactions that were not yet replicated may be lost.在
clusterSet.forcePrimaryCluster()clusterName參數為必要參數,並指定 InnoDB ClusterSet 中用於複本叢集的識別碼,如clusterSet.status()clustertwo如果您想要執行驗證並記錄變更,而不實際執行,請使用
dryRun選項。使用
invalidateReplicaClusters選項來命名任何無法連線或無法使用的複本叢集。這些會在容錯移轉程序期間標記為已失效。如果在程序期間發現您未命名的任何無法連線或無法使用的複本叢集,則會取消容錯移轉。在這種情況下,您必須修復並重新加入複本叢集,然後重試命令,或在重試命令時命名它們,並稍後修正它們。使用
timeout選項來定義在叢集的每個執行個體中,等待套用擱置交易的最大秒數。確保 GTID_EXECUTED 具有最新的 GTID 集。預設值是從dba.gtidWaitTimeout選項擷取的。
當您發出
clusterSet.forcePrimaryCluster()如果目標複本叢集符合要求,則 MySQL Shell 會執行下列工作
嘗試聯絡目前的主要叢集,如果實際上可以連線,則會停止容錯移轉。
檢查是否有任何未使用
invalidateReplicaClusters指定的無法連線或無法使用的複本叢集,如果發現任何一個,則會停止容錯移轉。將
invalidateReplicaClusters中列出的所有複本叢集標記為已失效,並將舊的主要叢集標記為已失效。檢查目標複本叢集是否在可用的複本叢集中,具有最新的 GTID 集。這牽涉到停止所有複本叢集中的 ClusterSet 複寫通道。
更新所有複本叢集上的 ClusterSet 複寫通道,以從目標叢集複寫做為新的主要叢集。
將目標叢集設定為 ClusterSet 中繼資料中的主要叢集,並將舊的主要叢集變更為複本叢集,儘管由於它標記為已失效,因此目前無法做為複本叢集運作。
在緊急容錯移轉期間,MySQL Shell 不會嘗試將目標複本叢集與目前的主要叢集同步,也不會鎖定目前的主要叢集。如果原始的主要叢集保持在線上,則應該在可以聯絡時立即將其關閉。
-
如果您有任何 MySQL Router 執行個體要切換為以新的主要叢集為目標,請立即執行。您可以將它們變更為追蹤主要叢集 (
"target_cluster": "primary"),或指定接管做為主要叢集的複本叢集 ("target_cluster": ")。例如新主要叢集名稱"mysql-js> myclusterset.setRoutingOption('Rome1', 'target_cluster', 'primary') or mysql-js> myclusterset.setRoutingOption('Rome1', 'target_cluster', 'clustertwo') Routing option 'target_cluster' successfully updated in router 'Rome1'.發出
clusterSet.routingOptions() 再次使用
extended選項,發出clusterSet.status()-
當您能夠再次聯絡舊的主要叢集時,首先請確保沒有應用程式流量正在路由至該叢集,並將其離線。然後依照第 8.9 節「InnoDB ClusterSet 修復和重新加入」中的程序,檢查交易並決定如何安排未來的 InnoDB ClusterSet 拓撲。
在緊急容錯移轉之後,並且 ClusterSet 的各部分之間存在交易集不同的風險,您必須將叢集隔離,使其無法寫入流量或所有流量。如需更多詳細資訊,請參閱在 InnoDB ClusterSet 中隔離叢集。
如果您在切換程序期間必須使任何複本叢集失效,當您能夠再次聯絡它們時,可以使用第 8.9 節「InnoDB ClusterSet 修復和重新加入」中的程序來修復它們,並將它們新增回 InnoDB ClusterSet。