MySQL NDB Cluster 8.1 手冊
MySQL NDB Cluster 8.0 手冊
NDB Cluster 內部手冊
NDB Cluster 定義為一或多個 MySQL 伺服器,提供對 NDBCLUSTER 儲存引擎的存取權 — 也就是對一組 NDB Cluster 資料節點(ndbd 處理程序)的存取權。從 Java 連線到 NDBCLUSTER 主要有三個存取路徑,列舉如下:
JDBC 與 mysqld。 JDBC 的運作方式是將 SQL 陳述式傳送至 MySQL 伺服器,並傳回結果集。使用 JDBC 時,您必須撰寫 SQL、管理連線,並複製結果集中您要在程式中用作物件的任何資料。與 MySQL 伺服器搭配使用的 JDBC 實作最常見的是 MySQL Connector/J。
Java Persistence API (JPA) 與 JDBC。 JPA 使用 JDBC 連線至 MySQL 伺服器。與 JDBC 不同的是,JPA 提供資料庫中資料的物件檢視。
ClusterJ。 ClusterJ 使用 JNI 橋接器連線至 NDB API,以直接存取
NDBCLUSTER。它採用基於領域物件模型的資料存取樣式,在許多方面與 JPA 所採用的樣式相似。ClusterJ 不依賴 MySQL 伺服器進行資料存取。
這些路徑顯示在以下 API 堆疊圖中
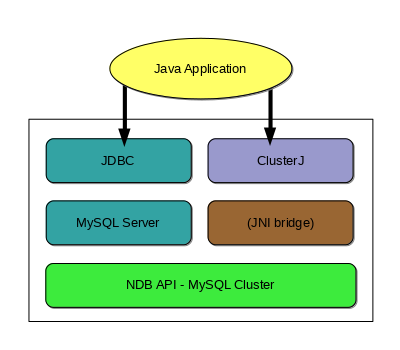
JDBC 與 mysqld。 Connector/J 透過 MySQL JDBC 驅動程式提供標準存取。使用 Connector/J,可以撰寫 JDBC 應用程式以與作為 NDB Cluster SQL 節點的 MySQL 伺服器搭配運作,其方式與其他 Connector/J 應用程式與任何其他 MySQL 伺服器執行個體搭配運作的方式非常相似。
如需詳細資訊,請參閱 第 4.2.3 節「搭配 NDB Cluster 使用 Connector/J」。
ClusterJ。 ClusterJ 是 NDBCLUSTER(或 NDB,NDB Cluster 的儲存引擎)的原生 Java 連接器,其樣式與 Hibernate、JPA 和 JDO 相同。如同其他永續性框架,ClusterJ 使用 Data Mapper 模式,其中資料表示為領域物件,與商務邏輯分開,將 Java 類別對應至儲存在 NDBCLUSTER 儲存引擎中的資料庫表格。
注意
NDBCLUSTER 儲存引擎通常(在 MySQL 文件和其他地方)簡稱為 NDB。「NDB」和「NDBCLUSTER」這兩個詞是同義詞,您可以在 CREATE TABLE 陳述式中使用 ENGINE=NDB 或 ENGINE=NDBCLUSTER 來建立叢集表格。
ClusterJ 不需要連線到 mysqld 處理程序,它可以透過動態程式庫 libnbdclient 中包含的 JNI 橋接器直接存取 NDBCLUSTER。然而,與 JDBC 不同,ClusterJ 不支援表格建立和其他資料定義作業;這些作業必須透過其他方式執行,例如 JDBC 或 mysql 用戶端。此外,ClusterJ 僅限於單一表格的查詢,並且不支援關係或繼承;如果您的應用程式需要支援這些功能,您應該使用其他類型的存取路徑。